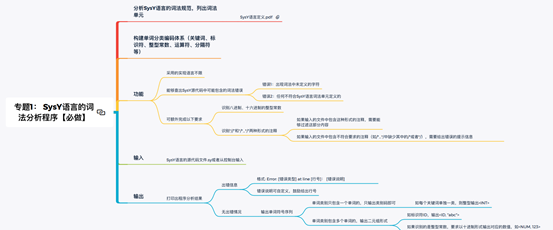
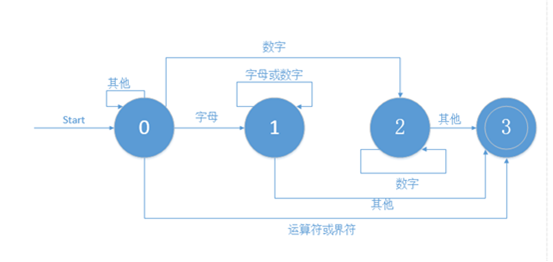
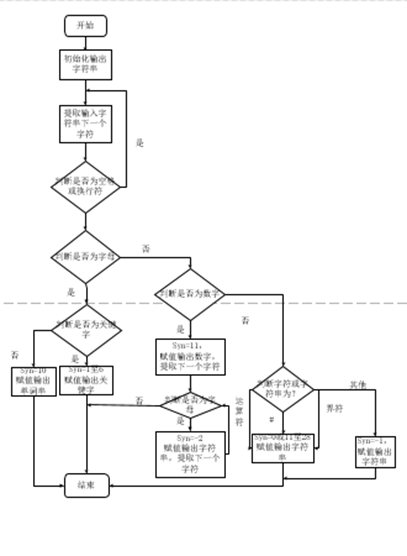
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
| import re
keyword=['auto','break','case','char','const',
'continue','default','do','double','else','enum',
'extern','float','for','goto','if','int','long',
'register','return','short','signed','sizeof','static',
'struct','switch','typedef','union','unsigned','void'
,'volatile','while']
operator = ['+','-','*','/','%','++','--','+=','-=','+=','/=',
'==','!=','>','<','>=','<=',
'&','|','^','~','<<','>>',
'&&','||','!',
'=',
]
delimiters = ['{','}','[',']','(',')','.',',',':',';']
def isIdentifier(str):
if len(str)==1:
return str[0]=='_' or str[0].encode().isalpha()
else:
return (str[0]=='_' or str[0].isalpha()) and str[1:].replace('_','').encode().isalnum()
def isKeywords(str):
if str in keyword:
return True
else:
return False
if __name__=='__main__':
identifier=[]
token=[]
filename=r'test\04_const_defn.sy'
fp=open(filename,encoding='utf-8',mode='r')
txt=fp.read()
lines = re.sub(r'\/\*[\s\S]*\*\/|\/\/.*','',txt).split('\n')
fp.close()
lines=[line.strip('\n').replace('\t','') for line in lines]
identifier=[]
flag=False
for line in lines:
word=''
if line=='':
continue
else:
i=-1
while(i+1<len(line)):
i=i+1
ch=line[i]
if ch==' ':
continue
if ch in delimiters:
token.append(f'<delimiter,{delimiters.index(ch)},\'{ch}\'>')
elif ch in operator:
next=line[i:i+2]
if next in operator:
token.append(f'<operator,{operator.index(next)},\'{next}\'>')
i=i+1
else:
token.append(f'<operator,{operator.index(ch)},\'{ch}\'>')
elif ch.isnumeric():
base=10
num=ch
if(ch=='0' and i+1<len(line) and line[i+1] in 'xboXBO'):
if(i+1<len(line) and line[i+1]=='x'):
num='0x'
base=16
i=i+1
elif(i+1<len(line) and line[i+1]=='x'):
num='0o'
base=8
i=i+1
elif(i+1<len(line) and line[i+1]=='b'):
num='0b'
base=2
i=i+1
while i+1<len(line) and (line[i+1] in '0123456789abcdefABCDEF'):
num=num+line[i+1]
i=i+1
else:
if not num in '0x0o0b':
token.append(f'<num,{int(num,base)}>')
elif isIdentifier(ch):
word=ch
while(i+1<len(line) and isIdentifier(line[i+1])):
word=word+line[i+1]
i=i+1
else:
if word in keyword:
token.append(f'<{word}>')
word=''
else:
if not word in identifier:
identifier.append(word)
token.append(f'<identifier,{identifier.index(word)},\'{word}\'>')
word=''
else:
print(f'Error at line {lines.index(line)+1}:不允许的字符')
continue
for i,x in enumerate(token):
print(x)
|